Home / Blog / Image Translation / Video Translation / Support / Donation / RSS
How to Align Text with Audio
You’ve got an audio or a video and the script of the speech. Now, you would like to align the text with the speech. Instead of manually creating the timelines, we can use a computer-aided approach:
- First, recognize the speech to get the timelines with the recognized words.
- Then, align the recognized text with the existing text.
- Finally, determining the alignment of the aligned text and the timelines based on the text length.
The computer-aided video/audio translation tool Silhouette is made for such a purpose.
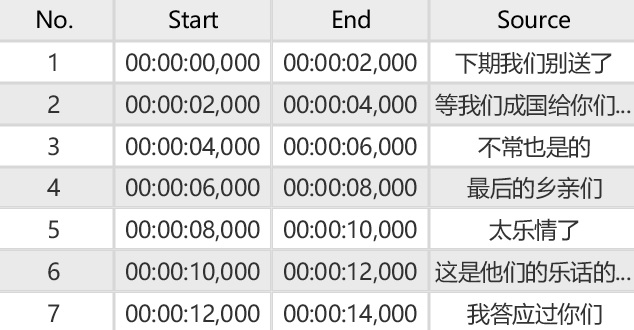
Recognized result:
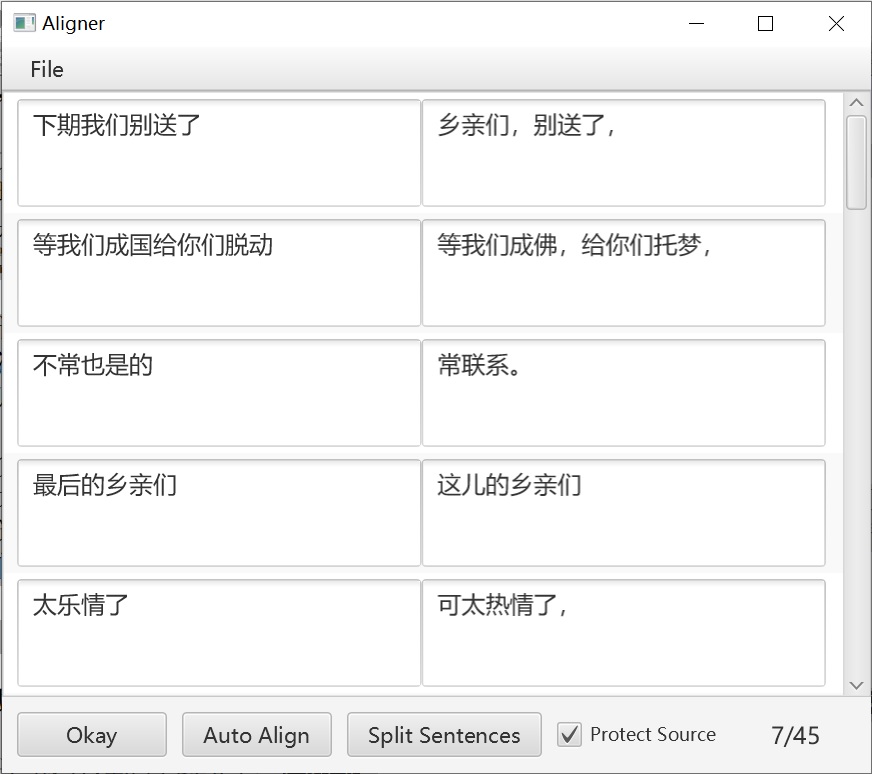
Aligner:
Aligned result:
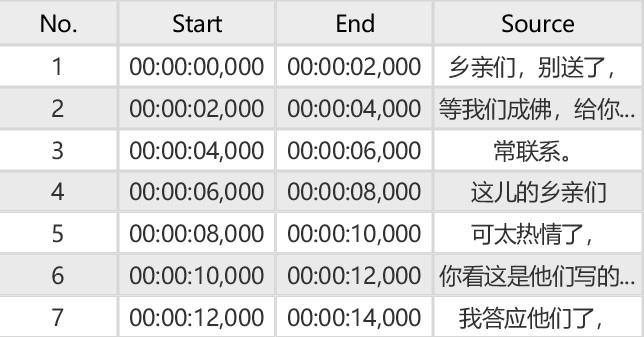
PS: if the recognized speech is accurate, we do not have to do this. This is for cases where the audio quality is not good, which leads to bad recognition results.
Video tutorial: https://www.youtube.com/watch?v=QWbFLkAUdC0
Further Reading
Forced alignment is the process of determining, for each fragment of the transcript, the time interval (in the audio file) containing the spoken text of the fragment.
A text fragment can have arbitrary granularity:
- a paragraph,
- a sentence,
- a word
There are many ways to achieve this. A simple method is to divide the speech based on syllables.
Generally, it is an automatic approach. But in order to get an accurate result, human intervention is needed. This is what Silhouette is used for.
© 2026 BasicCAT ― Powered by Jekyll and Textlog theme