Home / Blog / Image Translation / Video Translation / Support / Donation / RSS
Hardcoded Subtitle Extraction
Hardcoded (burned-in) subtitles are subtitles that blend directly into the video frames. This type of subtitle cannot be extracted directly. If we can’t find the original subtitle file and we want to extract the subtitle text and the corresponding timestamps, we need to use optical character recognition technology (OCR) for extraction.
Here is a simple extraction process of hardcoded subtitles: directly recognize the subtitles in each frame, and then determine which frames belong to the same subtitle line based on the position and content of the text to calculate the timeline.
But in practice, because OCR is a time-consuming operation, for 1 minute of a 25 FPS video, we need to process 1500 pictures, which may take tens of minutes. There is also a recognition rate problem, which can affect the results. So we need to optimize the process to improve the performance.
One approach is to use less time-consuming image processing methods to determine which frames contain subtitles, and then use an accurate OCR to recognize the text. There are already tools like VideoSubFinder and esrXP. However, this type of software uses traditional image processing methods, and the accuracy rate is not high enough. In this case, we can directly use the text detection method of an OCR software to determine which frames contain subtitles.
OCR is generally divided into two steps: detecting the text and recognizing the text. OCR’s text detection method is more accurate than traditional approaches, and since we skip the recognition step, it can also save time.
ImageTrans provides a hardcoded subtitle extraction tool that provides support for the above process. Next, we will introduce the use of the software with Empresses in the Palace as an example. Bilingual subtitles are provided in the Empresses in the Palace. Based on this bilingual subtitles, we can create a parallel corpus for language learning and research.
Subtitle Analysis
First, let’s take a look at what the subtitles in Empresses in the Palace look like. Here are a few screenshots:



We can see that the subtitles will have two lines, three lines, etc. The translated text may be scattered in multiple subtitles of the same original text.
Extract Video Frames
Open Silhouette and use its frame extractor to extract video frames:
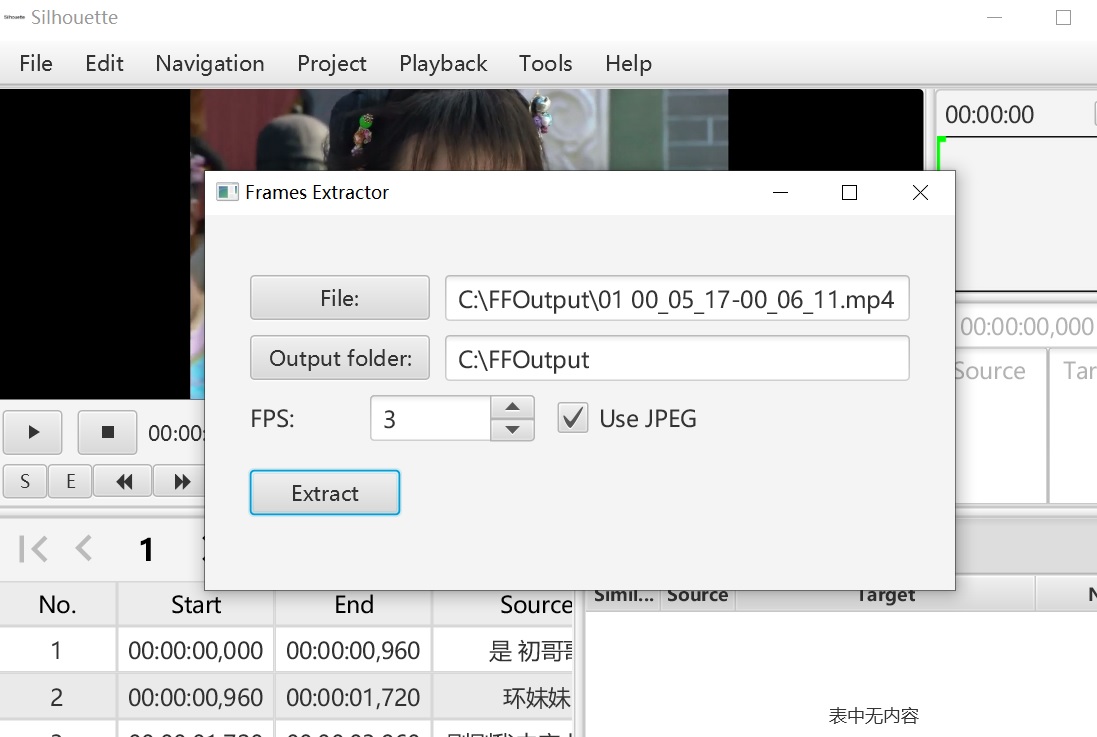
Here we can set FPS. When FPS is set to 3, only 3 frames are extracted per second. If we want to have accurate timestamps, we can make the FPS bigger, but it will take more time to process. If we just need the text and don’t need the time to be accurate, FPS can be set smaller.
Recognize Subtitles in the Video
Next, open ImageTrans and import the video frames we just extracted.
Open the video subtitle extractor through menu -> tools.
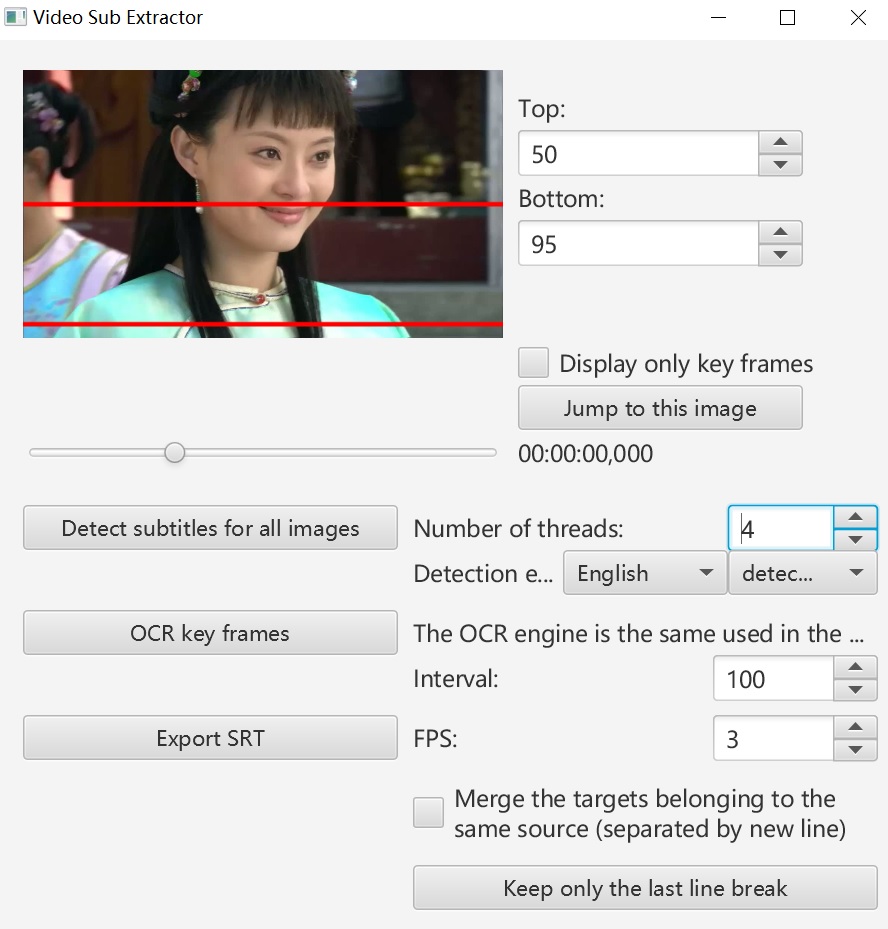
Set the boundary of the region to be recognized, select the detection engine as “detect only (PaddleOCR)”, set the number of threads as 4, and click “Detect subtitles in all images” to start detection. Here, we process a 54-second video. The FPS for extraction is set to 3 so there are 164 images to detect.
After the operation is completed, we can see that the subtitle lines in the image are detected.
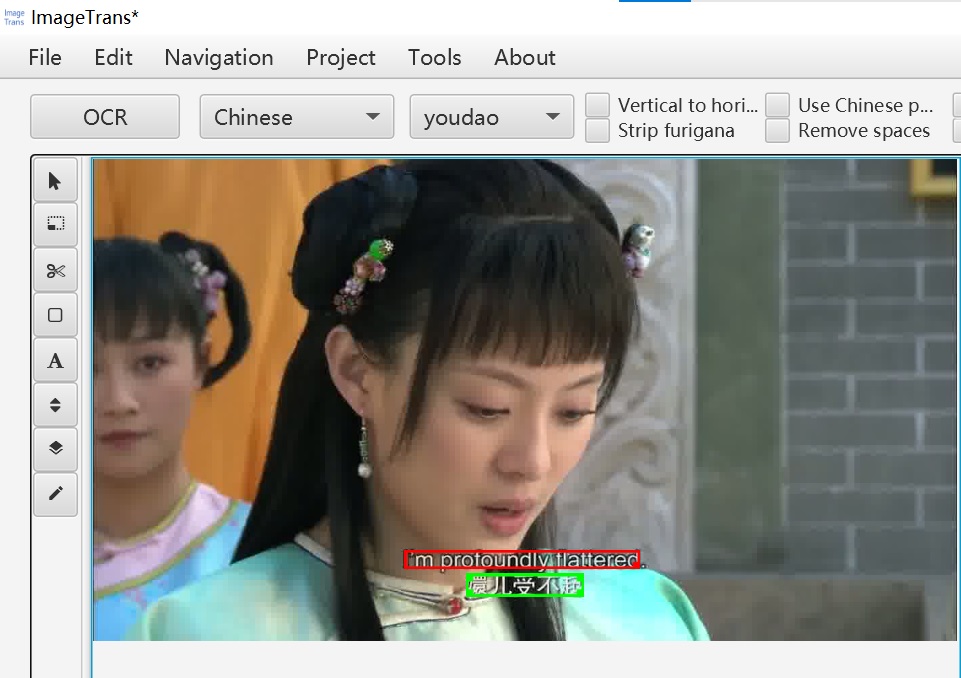
After that, we click “OCR all keyframes”, which recognizes the text in the subtitle images. Since we only recognize keyframes here, the number of images to be processed becomes 21.
We can see that an additional text box containing the recognized text is added.
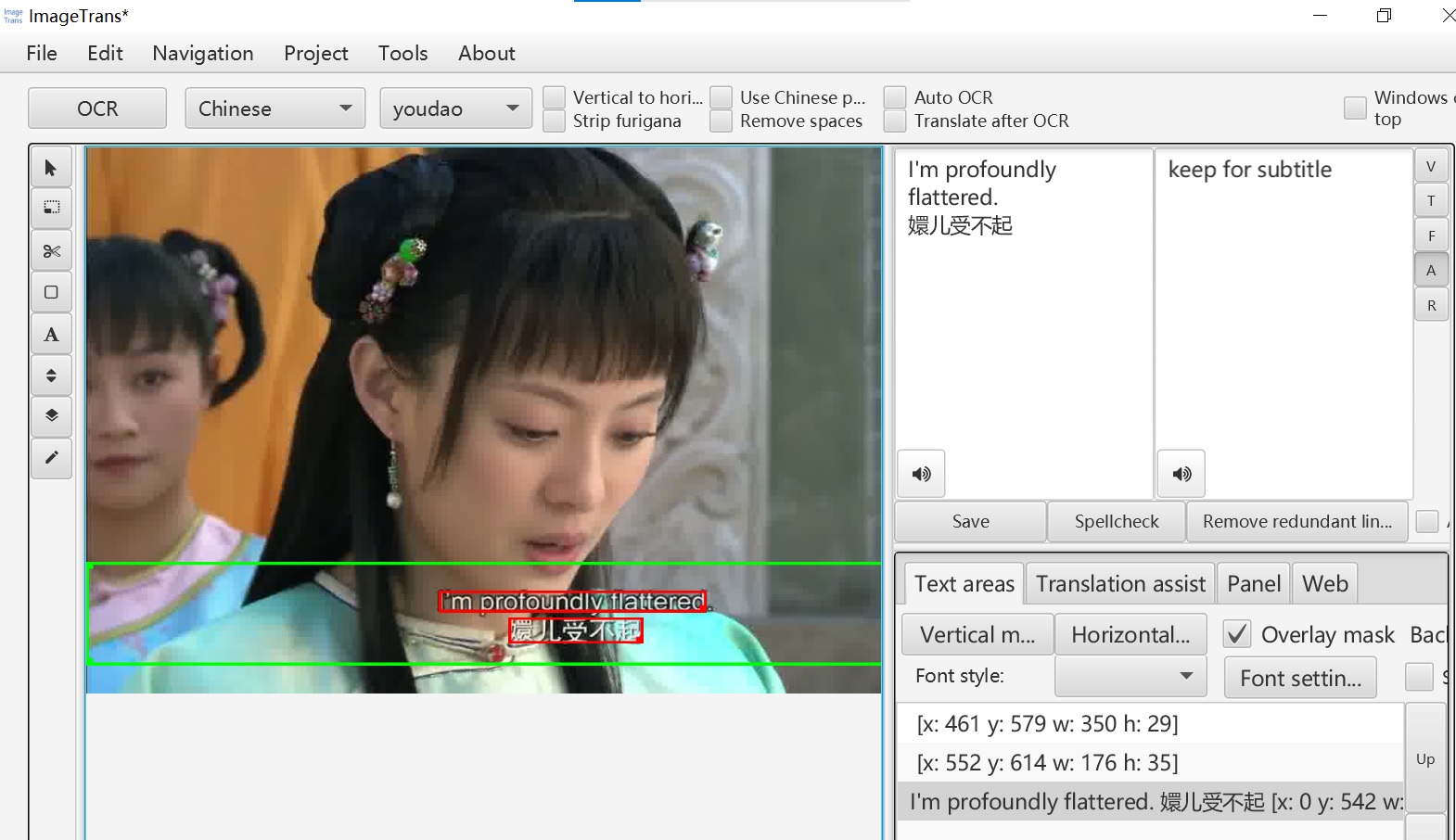
After that, we can export the subtitles as an SRT file.
Because it’s bilingual, there are some extra steps. First, before “OCR all keyframes”, uncheck “Auto remove line breaks”. Then in the video subtitle extractor, click “Keep only the last line break”. In this way, we can make the text into one line of source text, one line of target text.
Then tick the checkbox: “merge multiple targets belonging to the same source”. In this way, the scattered target text will be merged together.

Here are the extracted subtitles:
1
00:00:00,999 --> 00:00:02,664
- Shichu. - Huan.
实初哥哥 嬛妹妹
2
00:00:03,663 --> 00:00:04,995
I just checked up on your family.
刚刚我去府上请脉
3
00:00:05,328 --> 00:00:07,659
Your mother told me you'd come here to offer incense.
听甄伯母说你来这里进香了
4
00:00:07,992 --> 00:00:09,657
Simply for a stroll and-to-pass an idle hour.
出来走走 也是散心
5
00:00:11,322 --> 00:00:13,320
Huan, don't try to hide it from me.
嬛妹妹 你就不要再瞒我了
6
00:00:14,319 --> 00:00:17,982
I know you' ve been worried about the audition for many days.
我知道为了殿选之事 你已经烦恼多日了
7
00:00:19,647 --> 00:00:22,644
U may only do what I'm allowed. The rest I leave to fate.
嬛儿是尽人事以听天命
8
00:00:23,643 --> 00:00:26,640
Huan, when my father lived, he often said,
嬛妹妹 家父在世的时候常说
9
00:00:26,973 --> 00:00:28,971
"A jade vessel is the symbol of a pure heart.
一片冰心在玉壶
10
00:00:29,304 --> 00:00:32,301
He wanted me to give this to my future-
他让我把此壶 交予我们温家未来的
11
00:00:33,300 --> 00:00:34,965
It is my own wish as well.
其实这也是我一直以来的心意
12
00:00:35,298 --> 00:00:38,295
If you accept this, you won't be called to the audition.
你若接受的话 就不用再去宫中殿选了
13
00:00:40,626 --> 00:00:43,290
In the time of the Shunzhi Emperor, it was decreed
顺治爷在世的时候就定下定例
14
00:00:43,623 --> 00:00:46,953
that girls qualified to join the harem may not marry before the audition.
所有未经选看的秀女 断不可私下结亲
15
00:00:47,619 --> 00:00:51,948
Though you intend to help, you need not give me such a valuable item.
实初哥哥想一时救急 也不必拿出这么贵重的东西来
16
00:00:52,614 --> 00:00:53,946
I'm profoundly flattered.
嬛儿受不起
The advantage of using ImageTrans to extract hardcoded subtitles is that we can intervene and modify the whole process, and different OCR engines can be selected for different languages.
After the subtitles are extracted, they can also be imported into Silhouette, a computer-aided audio-video translation software, and adjusted with the help of the waveform.
Test Data
Test video: An old video titled “Sisters Swap Husbands” with a duration of 1 hour and 41 minutes (https://www.bilibili.com/video/BV1E4411L7bN/)
Test machine: HP ZBook Studio G3, i7 6820HQ CPU, DDR4-2133 16GB
Video Sub Finder: Processes the video directly, identifies 5,028 subtitle images, takes 20 minutes
ImageTrans+PaddleOCR: Processes a total of 18,100 images, identifies 1,373 subtitle images, takes 6 minutes
Video Sub Finder uses traditional methods, resulting in many false positives for non-subtitle images, and the processing takes longer. ImageTrans performs much better.
Recommended Text Detection Engine
ImageTrans supports text detection using YOLO object detection as well as various OCR engines.
The recommended OCR engine is: PaddleOCR (2.x), which offers fast processing speed, good support for concurrency, and excellent performance even on machines without a dedicated GPU when running on CPU alone. It can be downloaded here: https://github.com/xulihang/ImageTrans_plugins/tree/master/paddleOCR
Video Tutorials
- Traditional approach (VideoSubFinder + ImageTrans): https://www.youtube.com/watch?v=__MTiAtqrTs
- OCR approach (Silhouette + ImageTrans): https://www.youtube.com/watch?v=5zEDfrXUAdI
© 2026 BasicCAT ― Powered by Jekyll and Textlog theme