首页 / 博客 / 图片翻译 / 音视频翻译 / 支持 / 捐助 / 订阅
PDF论文翻译与转换为Markdown
在学术工作中,我们可以会遇到一些外语PDF。英语可能还好,但读起来不如中文母语效率高。而其它小语种,比如法语、日语,就直接看不懂了。这时我们需要对其进行翻译。可以在PDF原文的位置上覆盖上译文,或者直接转换成Markdown等格式,在手机的小屏幕上也方便地阅读。
翻译PDF论文有一些特别的点:
- PDF论文排版复杂,有多栏布局、公式、表格、图片、尾注等各种内容,需要进行版面分析,确定这些内容的位置和阅读顺序。
- PDF的文字一般可以直接提取,不需要额外OCR。但PDF的文字信息可能存在缺漏、编码错误(乱码)等各种问题,这个时候还是需要使用OCR。
- 有很多不需要提取和翻译的文本(非译元素),需要进行过滤。
本文会使用ImageTrans这款图片OCR和翻译软件,翻译以下PDF。
《視覚言語モデルは漫画のオノマトペを翻訳できるか?》: PDF链接
操作步骤
-
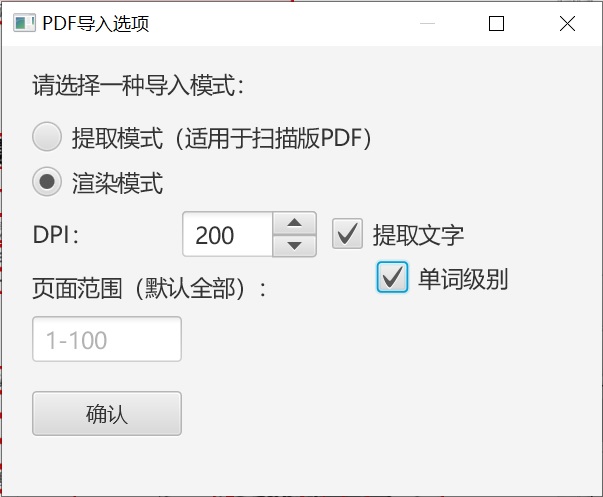
基于“文档”模板新建一个项目,导入PDF。ImageTrans会转换PDF为图片进行处理。有一些参数需要设置。如果是扫描版PDF,可以选择提取图片模式,处理速度很快。如果是文字可以复制的PDF,使用默认的渲染模式,并勾选提取文字,同时以单词为级别提取。
-
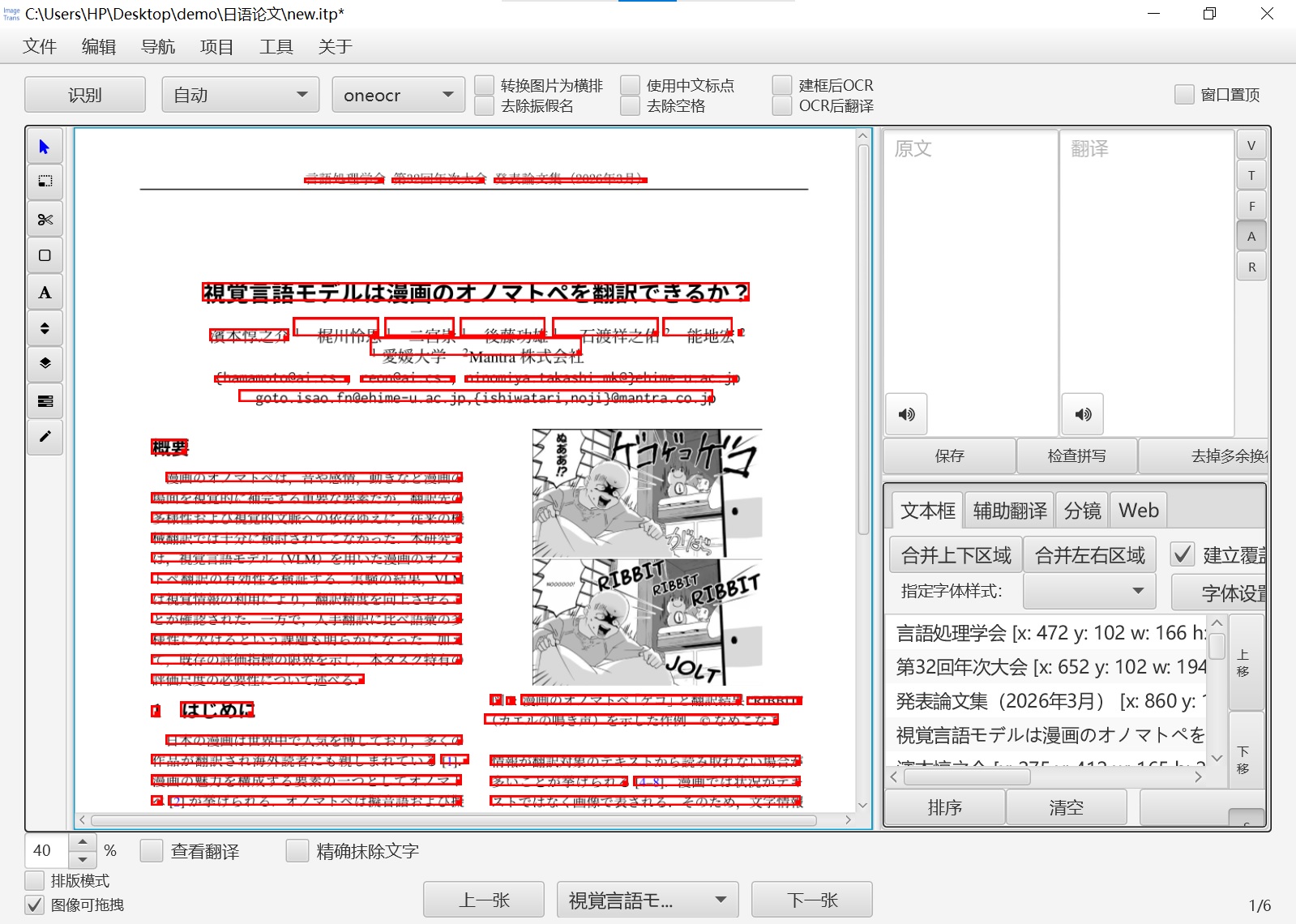
如果PDF自带的文字信息提取出来效果不好或者没有自带文字,可以选择一个OCR引擎进行识别,比如日语可以用rapid或者oneocr。可以点菜单-编辑-自动识别文字,看看识别一张图片的效果。
这里示例PDF的文字提取出来的效果不错。
-
通过菜单-项目-批处理-自定义工作流,打开工作流设置界面。需要针对当前PDF做些设置。比如这个PDF不需要检测文字、需要去除分镜外的区域、需要选择分镜检测引擎为效果较好的Deepseek-OCR。分镜这里指代各种布局,比如段落、图表等等。
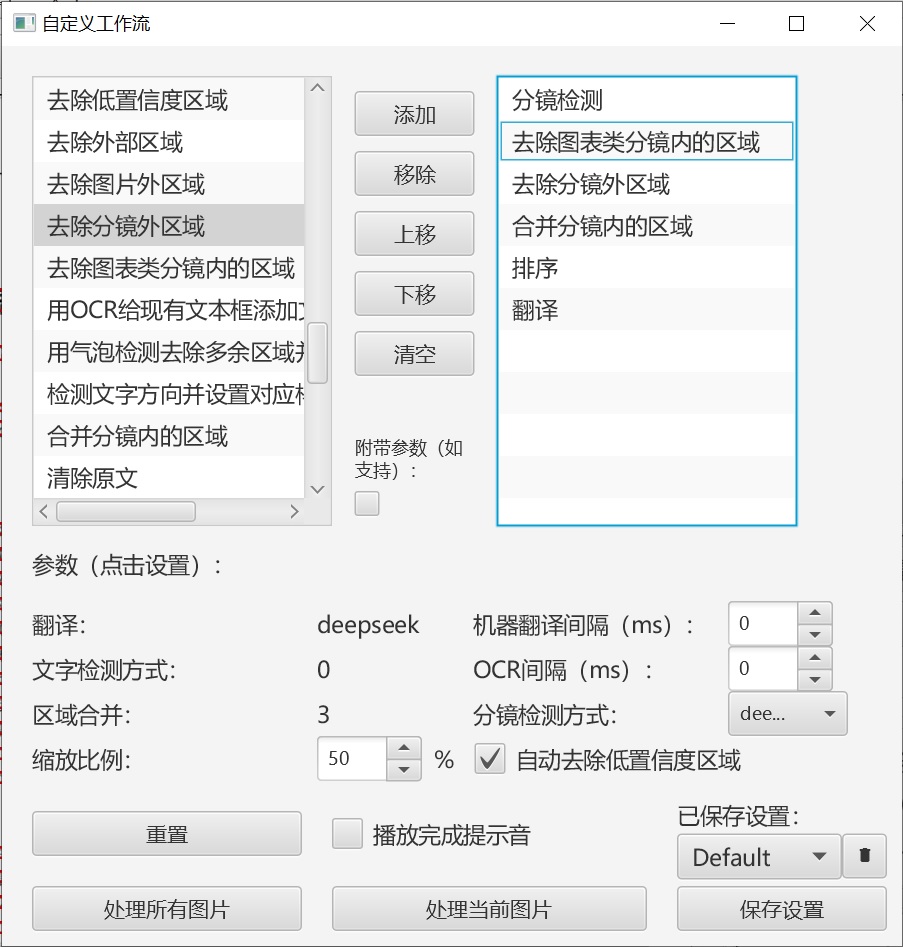
每个操作的说明:
- 分镜检测:使用设置的Deepseek-OCR进行布局分析
- 去除图表类分镜内的区域:图表中的文字不需要翻译,直接去除。图表导出为markdown时会以图片形式保存。
- 去除分镜外的区域:去除一些页脚等文字,因为它们不会被Deepseek-OCR检测为页面布局成分
- 排序:将文字区域根据分镜顺序进行排序,保证阅读顺序正确
- 翻译:使用Deepseek等引擎进行翻译
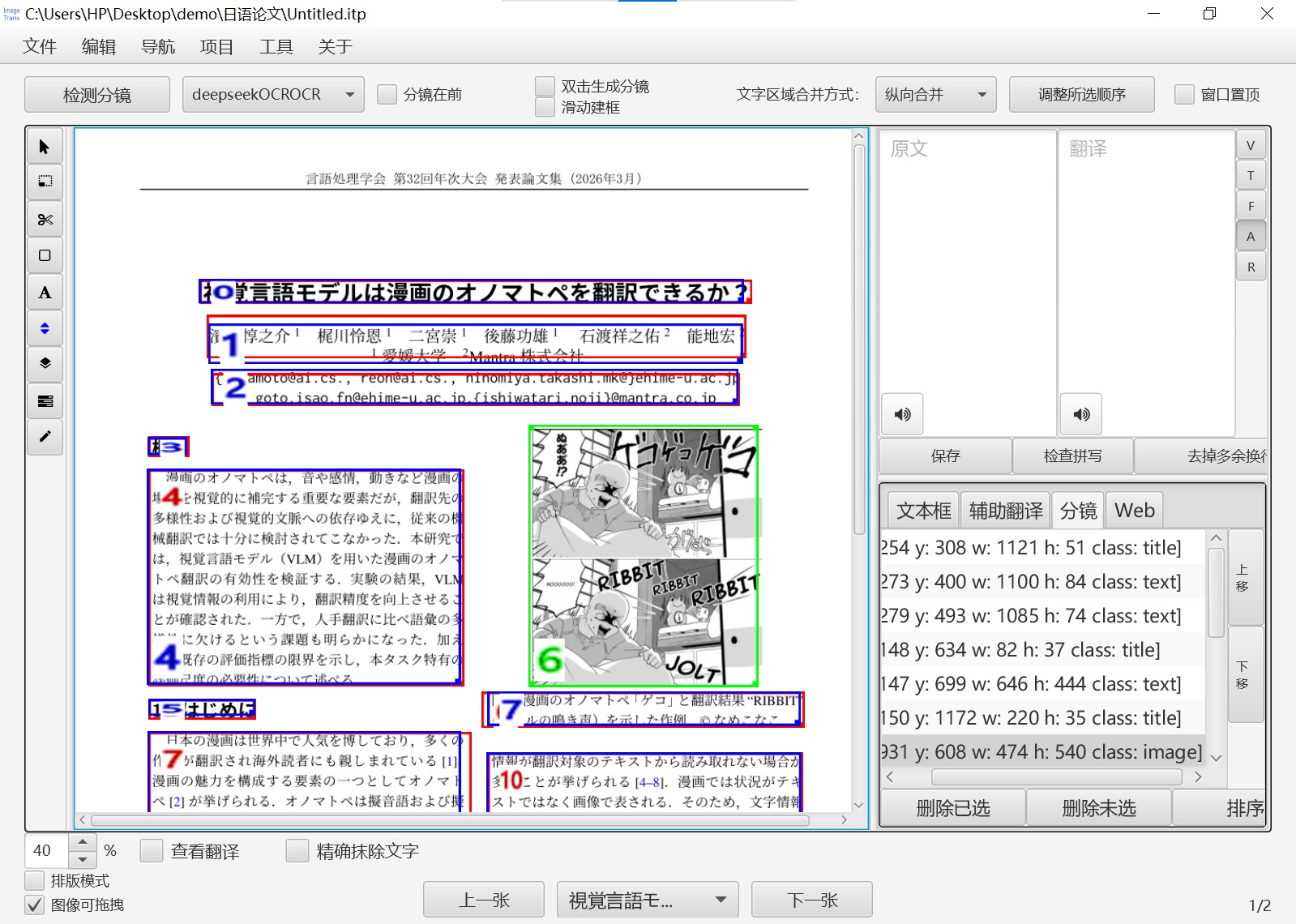
下面是执行好自定义工作流,切换工具栏为排序模式时的界面:
-
点击左下角“查看翻译”,可以看到PDF论文页面的翻译版本。
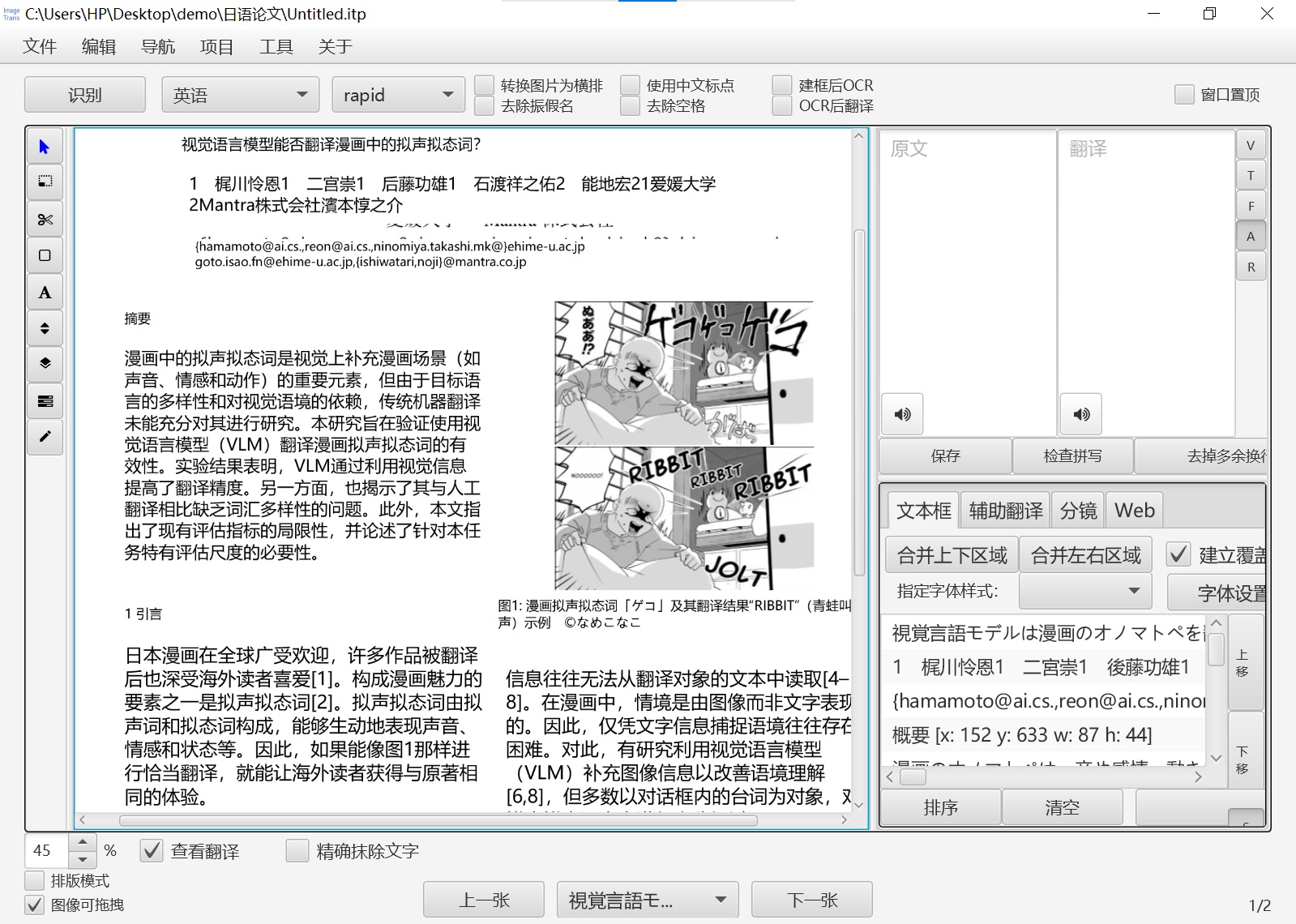
-
点菜单-文件-导出-markdown,可以将结果导出为markdown文件,方便在手机上查看或者给AI进行分析。因为markdown不像PDF那样,文字有位置信息,所以导出时对文字顺序是否正确的要求较高。通过Deepseeek-OCR布局分析,阅读顺序一般都是正确的。如果有错误,也可以在ImageTrans中修正。
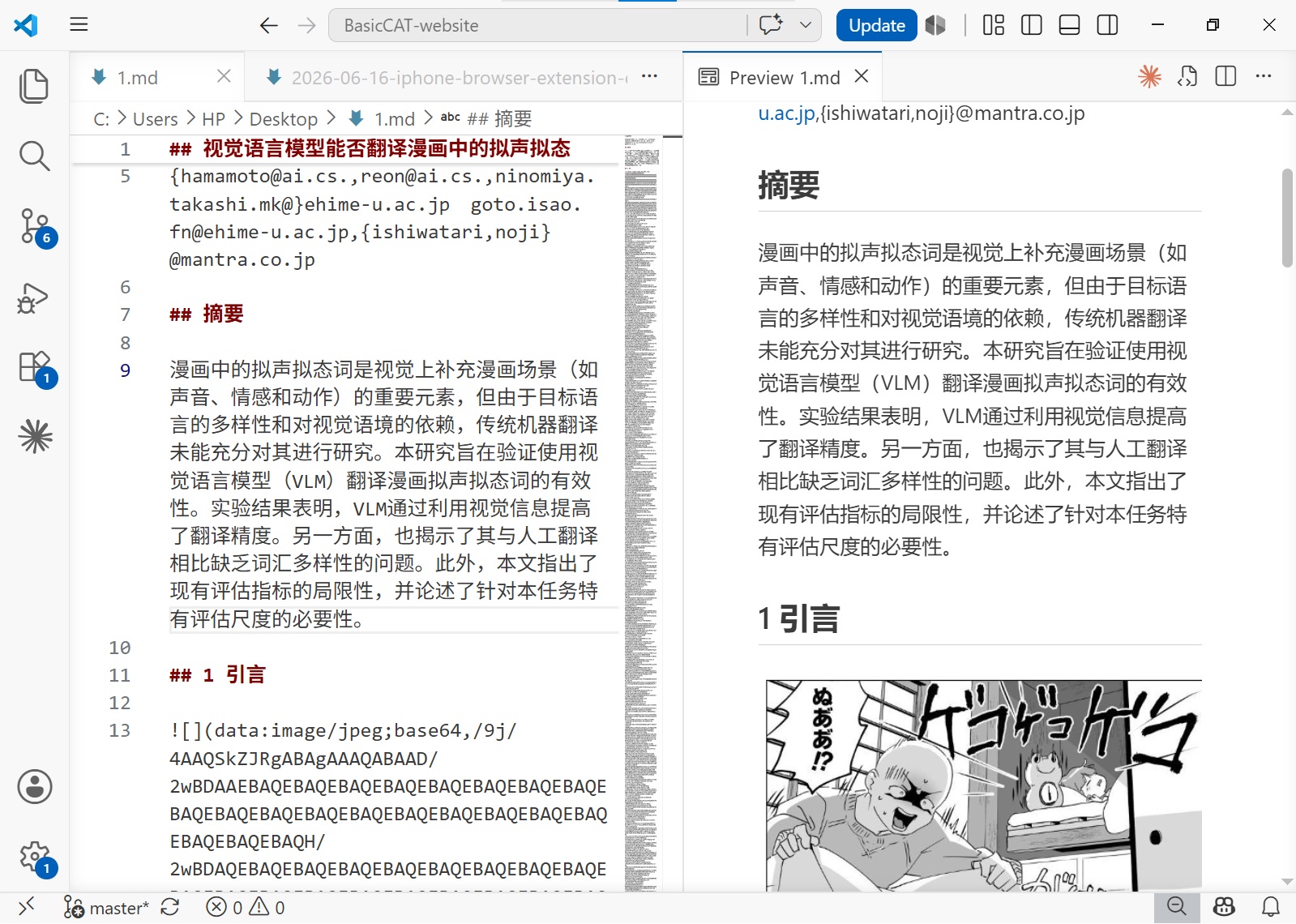
除了导出为markdown,也支持导出为PDF、HTML等其它格式。
配置
使用DeepSeek-OCR需要在偏好设置里配置硅基流动的API密钥:https://cloud.siliconflow.cn/models?target=deepseek-ai/DeepSeek-OCR
另外也支持本地运行。
除了DeepSeek-OCR,也可以使用GLM和MinerU等其它大模型进行布局分析。
系列文章
© 2026 BasicCAT ― Powered by Jekyll and Textlog theme